Today, we create a ceph network storage on our Centos 8 Stream with cephadm command. We will installing with manual page: https://docs.ceph.com/en/pacific/install/
In this example, we will have three systems (nodes), with identical HW resources (4 GB ram, 4 vCPU, two NICs – one internal for ceph and one for world, and dedicated 4 TB SSD disk for ceph storage). In this article, every command must be run on all nodes. Public network is 192.168.1.0/24 and Ceph separate network is 192.168.2.0/24
So, as a first step, we need to set up our Centos for synchronized time.
Setting up time
As the first step, we must set up a time, I use chrony:
dnf install chrony -y systemctl enable chronyd timedatectl set-timezone Europe/Bratislava timedatectl
Now, edit some variables in configurations file for chronyd. Add some servers from pool, and edit local subnets, where we delived time:
vim /etc/chrony.conf pool 2.centos.pool.ntp.org iburst pool 1.centos.pool.ntp.org iburst pool 3.centos.pool.ntp.org iburst
Now start/restart our service, and check, if it is working:
systemctl restart chronyd systemctl status chronyd.service chronyc sources
Create hostnames, ssh rsa-keys and update
Now, we must edit on all nodes our hostnames, set it permanent:
hostnamectl set-hostname ceph1
Now, add all hostnames, and IPs to file /etc/hosts:
tee -a /etc/hosts<<EOF 192.168.1.1 ceph1 192.168.1.2 ceph2 192.168.1.3 ceph3 EOF
Now, create rsa-key pair, for password-less connect to and from each node for root user for installing and updating:
ssh-keygen -t rsa -b 4096 -C "ceph1" means: -b bits. Number of bits in the key to create -t type. Specify type of key to create -C comment
And copy it to other nodes:
for host in ceph1 ceph2 ceph3; do ssh-copy-id root@$host done
Now update:
dnf update -y dnf install podman gdisk jq -y -reboot-
Preparing for ceph
Now, setup a yum/dnf based repository for ceph packages and updates and install package cephadm:
dnf install -y centos-release-ceph-pacific.noarch dnf install -y cephadm
Now, we can Bootstrap a new cluster. The first step in creating a new Ceph cluster is running the cephadm bootstrap command on the Ceph cluster’s first host. The act of running the cephadm bootstrap command on the Ceph cluster’s first host creates the Ceph cluster’s first “monitor daemon”, and that monitor daemon needs an IP address. You must pass the IP address of the Ceph cluster’s first host to the ceph bootstrap command, so you’ll need to know the IP address of that host.
Now, we can bootstrap our first monitor by command (only on one node!!!):
cephadm bootstrap --mon-ip 192.168.1.1 --cluster-network 192.168.2.0/24
And after some time, we have a working cluster. And we can connect to dashboard.
Generating a dashboard self-signed certificate... Creating initial admin user... Fetching dashboard port number... firewalld ready Enabling firewalld port 8443/tcp in current zone... Ceph Dashboard is now available at: URL: https://ceph1.example.com:8443/ User: admin Password: tralala Enabling client.admin keyring and conf on hosts with "admin" label You can access the Ceph CLI with: sudo /usr/sbin/cephadm shell --fsid xxx -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring Please consider enabling telemetry to help improve Ceph: ceph telemetry on For more information see: https://docs.ceph.com/docs/pacific/mgr/telemetry/
Now, we can log in with web interface (dashboard). At first login, we use mentioned username and password and we have to change our password.
But our cluster is not finished, yet 
So, we continue. On first node (ceph1), where we bootstrap ceph, we can view status ceph by command:
cephadm shell -- ceph -s
cluster:
id: 77e12ffa-c017-11ec-9124-c67be67db31c
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph1 (age 26m)
mgr: ceph1.rgzjga(active, since 23m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
But checking status of ceph by this way is difficulty, so we install ceph-common package by cephadm on every node:
cephadm add-repo --release pacific
cephadm install ceph-common
ceph status
cluster:
id: 77e12ffa-c017-11ec-9124-c67be67db31c
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph1 (age 27m)
mgr: ceph1.rgzjga(active, since 24m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
Now, we copy ceph ssh pubkeys to other hosts for working each-other with ceph and passwordless:
ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph2 ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph3
And now, we can add this nodes to ceph, runnig from first node (where we bootstrap ceph).After this commands, wait some time, for podman to deploy containers (monitor, manager). And label them as admin.
ceph orch host add ceph2 192.168.1.2 ceph orch host add ceph3 192.168.1.3 ceph orch host label add ceph2 _admin ceph orch host label add ceph3 _admin
Now, we can look, which disks are available for us:
ceph orch device ls HOST PATH TYPE DEVICE ID SIZE AVAILABLE REJECT REASONS ceph1 /dev/sda ssd QEMU_HARDDISK_drive-scsi2 4000G Yes ceph2 /dev/sda ssd QEMU_HARDDISK_drive-scsi2 4000G Yes ceph3 /dev/sda ssd QEMU_HARDDISK_drive-scsi2 4000G Yes
So, now we can create an OSD disks from these devices.
ceph orch daemon add osd ceph1:/dev/sda
Created osd(s) 0 on host 'ceph1'
ceph orch daemon add osd ceph2:/dev/sda
Created osd(s) 1 on host 'ceph2'
ceph orch daemon add osd ceph3:/dev/sda
Created osd(s) 2 on host 'ceph3'
ceph -s
cluster:
id: 77e12ffa-c017-11ec-9124-c67be67db31c
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1,ceph3,ceph2 (age 8m)
mgr: ceph1.vsshgj(active, since 8m), standbys: ceph3.ctsxnh
osd: 3 osds: 3 up (since 21s), 3 in (since 46s)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 15 MiB used, 11 TiB / 11 TiB avail
pgs: 1 active+clean
Now, if we want create a ceph filesystem cephfs, we must create two pool. One for data and one for metadata. so, execute commands below on one ceph node:
ceph osd pool create cephfs_data ceph osd pool create cephfs_metadata ceph fs new cephfs cephfs_metadata cephfs_data
Now, log into Ceph dashboard a we can see, that health is RED and there is error.We must create a mds services:
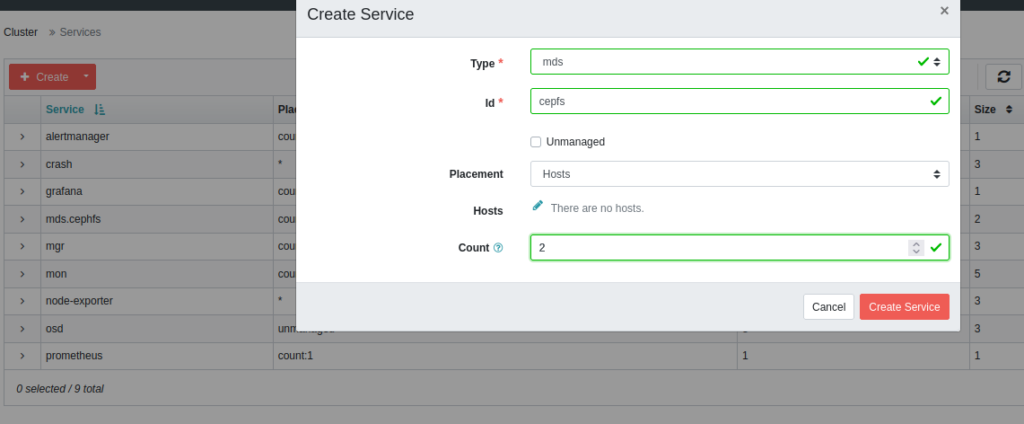
This deploys mds services to our nodes (one become active and one become standby).
Now, we can continue by command line and create an user, which can mount and write to these cephfs:
ceph auth add client.cephfs mon 'allow r' osd 'allow rwx pool=cephfs_data' ceph auth caps client.cephfs mds 'allow r,allow rw path=/' mon 'allow r' osd 'allow rw pool=cephfs_data' osd 'allow rw pool=cephfs_metadata' #and see our caps: ceph auth get client.cephfs [client.cephfs] key = agvererbrtbrttnrsasda/a5/dd== caps mds = "allow r,allow rw path=/" caps mon = "allow r" caps osd = "allow rw pool=cephfs_data"
Now, we can export or copy out our key and save it to a file. And now, we can mount those cephfs on another linux:
mount -t ceph ceph1.example.com:/ /mnt/cephfs -o name=cephfs,secretfile=/root/cephfs.key -v df -h Filesystem Size Used Avail Use% Mounted on 192.168.1.1:/ 3.5T 0 3.5T 0% /mnt/cephfs
If we want check, if we have enabled compression, so, execute:
ceph osd pool get cephfs_data compression_algorithm
Error ENOENT: option 'compression_algorithm' is not set on pool 'cephfs_data'
ceph osd pool get cephfs_data compression_mode
Error ENOENT: option 'compression_mode' is not set on pool 'cephfs_data'
If we want compression, enable it and set algorithm. Mode of compression, you can learn: read about – https://docs.ceph.com/en/latest/rados/operations/pools/
We can see, that there are data, but no compression:
ceph df detail

So enable it on both cephfs pools:
ceph osd pool set cephfs_data compression_mode aggressive
ceph osd pool set cephfs_data compression_algorithm lz4
ceph osd pool set cephfs_metadata compression_mode aggressive
ceph osd pool set cephfs_metadata compression_algorithm lz4
# and see:
ceph osd pool get cephfs_data compression_algorithm
compression_algorithm: lz4
ceph osd pool get cephfs_data compression_mode
compression_mode: aggressive
And after som copy data, we can see:

Have a nice day